 Nicht nur die Schach-Szene befindet sich in Aufruhr: AlphaZero hat sich Go, Shogi und Schach selbst beigebracht und wurde binnen 24 Stunden zum jeweils stärksten Spieler der Welt. Das ändert einiges, was Menschen über diese Spiele in den letzten Jahrhunderten gelernt haben. Doch was bedeutet das für den menschlichen Schachspieler? Was sind die neuen Erkenntnisse, die uns der Google-Computer beibringen könnte?
Nicht nur die Schach-Szene befindet sich in Aufruhr: AlphaZero hat sich Go, Shogi und Schach selbst beigebracht und wurde binnen 24 Stunden zum jeweils stärksten Spieler der Welt. Das ändert einiges, was Menschen über diese Spiele in den letzten Jahrhunderten gelernt haben. Doch was bedeutet das für den menschlichen Schachspieler? Was sind die neuen Erkenntnisse, die uns der Google-Computer beibringen könnte?
Doch langsam: Googles Tochter DeepMind konnte im Spiel Go bereits mit seiner Software AlphaGo die Nummer 1 der Weltrangliste besiegen. Im Oktober 2017 setzte sie mit AlphaGo Zero noch eines drauf, nur um im November mit AlphaZero dann endgültig Schlagzeilen zu machen: AlphaZero besteht aus einem neuronalen Netz, dem man die Grundregeln von Go, Schach und Shogi (der japanischen Variante von Schach) beigebracht hat und das man anschließend mit sich selbst trainieren lies.
Für Schach standen der Software dabei nur die Grundregeln des Spieles zur Verfügung. Kein Eröffnungsbuch, keine Endspiel-Datenbanken und auch sonst keine Wahrscheinlichkeitsverteilungen, mit denen traditionelle Schachprogramme gefüttert werden. Die Rechenleistung jedoch, die dem Programm in dieser Lernphase zur Verfügung stand, war enorm: Es dürfte sich um mehr als 5.000 Spezialchips mit dem Namen TPU (Tensor Processing Unit) gehandelt haben. Das – nach wenigen Stunden – fertig trainierte AlphaZero lief dann auf einer einzelnen Maschine mit „nur“ 4 TPUs und trat gegen die bisher stärksten Programme im jeweiligen Spiel an, die jeweils 64 Prozessorkerne zur Verfügung hatten. Pro Spielzug hatte jede Software 1 Minute Zeit. Eher wie ein Mensch als eine Maschine betrachtet AlphaZero jedoch weniger Stellungen als „traditionelle“ Computerprogramme. Die Publikation führt aus, dass es bei Schach „nur“ 80.000 Stellungen pro Sekunde sind, verglichen mit Stockfishs 70 Millionen Stellungen pro Sekunde.
Unter anderem Schlug bei diesem Turnier AlphaZero das beste Schachprogramm, Stockfish, und das beste Shogi-Programm, Elmo, haushoch. Auch bei Go gewann die Software von DeepMind – zwar nicht ganz so überlegen, aber doch. Was aber zu erwähnen ist: Bedenken gab es von einigen Schach-Großmeistern, dass das Turnier nicht nur im Hinblick auf die Rechenleistung nicht ganz fair war: Stockfish durfte bei den Partien ebenfalls kein Eröffnungsbuch verwenden. Jedoch ist der Grundtenor der, dass dies am finallen Ergebnis nichts geändert hätte.
Die Fa. DeepMind hat nun ein Paper veröffentlicht, in dem zumindest etwas Einblick in die Schachpartien und in die Schach-Lernphase von AlphaZero gegeben wird.
Was können wir von AlphaZero lernen?
Die Frage, die sich Schachspielern stellt, ist die: Was kann man von einem neuronales Netz, das sich ohne dem jahrhundertaltem Wissen von Eröffnungen und Zugfolgen Schach selbst beigebracht hat, lernen?
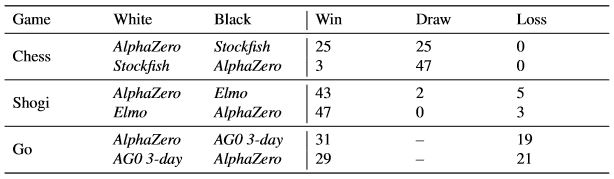
So könnte schon das Ergebnis des Turniers einige Schlüsse zulassen: Beim Schachturnier gegen Stockfish gewann AlphaZero 25 mal und remisierte 25 mal mit Weiß, während es mit Schwarz 3 mal gewonn und 47 mal Remis spielte. AlphaZero verlor kein einziges Spiel und beendete das Turnier mit 64:36.
Dies zeigt, dass die Farbe Weiß durchaus zu präferieren ist und der Beginn der Partie doch einen eklatanten Vorteil bietet.
Eröffnungen
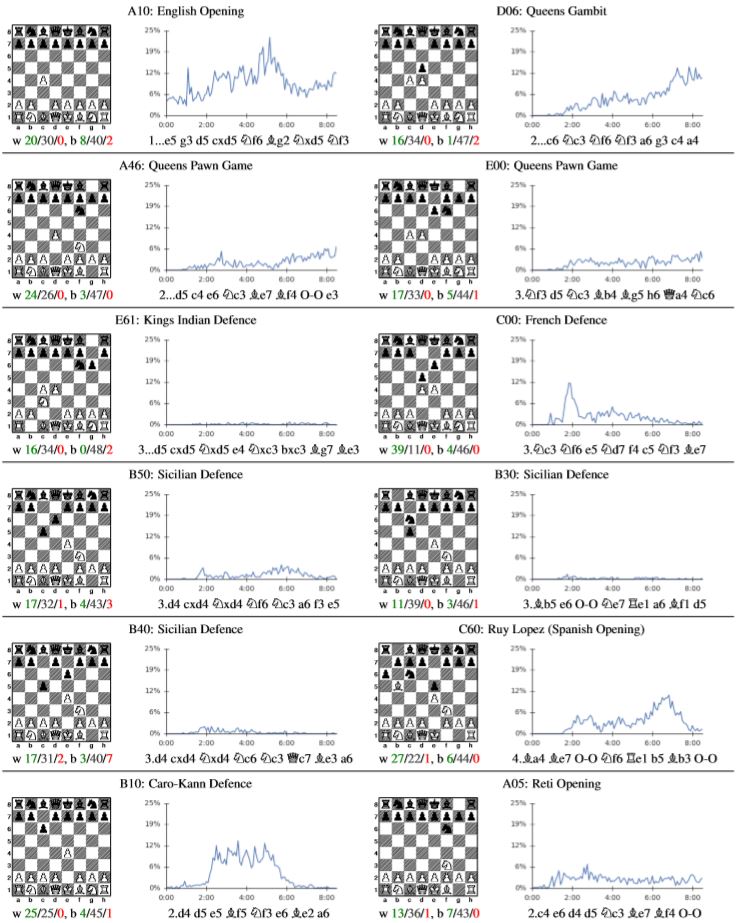
Auch bei den Eröffnungen gibt sich ein interessantes Bild: AlphaZero hat in der Lernphase unzählige Partien gegen sich selbst gespielt. Dabei hat AlphaZero – wie gesagt ohne Vorwissen – einen Großteil der traditionellen Eröffnungen von selbst wiederentdeckt. Andere hat es kurz probiert, aber dann – im Lernfortschritt – wieder verworfen. Die Grafik zeigt, welche Eröffnungen mit welcher Häufigkeit (im Zeitablauf der Lernphase) von AlphaZero angewendet wurden.
Mit der Zeit erhöhte die Software die Anzahl der Öffnungen, die esbevorzugte und reduzierte die, die es nicht mochte: So ist die Königsindische Verteidigung nicht die Eröffnung der Wahl. Auch die Begeisterung für die Französische Eröffnung ebbte immer mehr ab. Am Damengambit und an der Englischen Eröffnung fand das Programm jedoch immer mehr Gefallen. Für die Sizilianische Verteidigung konnte sich AlphaZero gar nicht begeistern.
Diskussion im Netz
Ob und wie man die Ergebnisse von AlphaZero auf das eigene Spiel umsetzen kann, wird im Netz heftig diskutiert. Beispielsweise können Sie sich hier der Diskussion anschließen: https://www.chess.com/forum/view/chess-openings/are-you-changing-openings-as-a-result-of-alpha-go
Quellen
- White-Paper: https://arxiv.org/pdf/1712.01815.pdf
- Chess.com: AlphaZero vs. Stockfish: https://www.chess.com/de/news/view/google-s-alphazero-besiegt-stockfish-in-einem-100-partien-vergleich-3971
- c’t-Magazin, Ausgabe 2/2018; S. 30 f.
